Performance
Cocoa is designed for high performance on modern GPU and CPU architectures. This page presents benchmark results comparing Cocoa with ADCIRC on a representative large-scale simulation, including strong-scaling behavior in CPU-MPI mode and single-GPU performance across three GPU generations.
Benchmark Configuration
The benchmark is a Hurricane Katrina (2005) hindcast with the following characteristics:
Mesh size: 1,568,749 nodes
Forcing: Tidal boundary, tidal potential, and hurricane wind and pressure fields
Time step: 2 s for both the implicit and explicit (lumped-mass) solvers, for both models
Simulated duration: 25 days
ADCIRC runs use double precision throughout. Cocoa computes in double precision with single-precision storage for bandwidth-bound fields.
Hardware:
CPU (PSC Bridges-2): dual-socket AMD EPYC 7742 64-core nodes (128 cores per node), 128 to 1024 MPI ranks (1 to 8 nodes)
GPU (Lambda Labs): NVIDIA H100 (SXM5, host Intel Platinum 8480+) and NVIDIA B200 (SXM6, host Intel Platinum 8592+), single device
GPU (workstation): NVIDIA V100 (host AMD Ryzen 9 9950X), single device
Both solvers use the same time step (2 s) and run for the same simulated duration, so the implicit and explicit results are a direct, step-for-step comparison. Results are still presented separately per solver because they exercise different work per step.
Implicit Solver Results
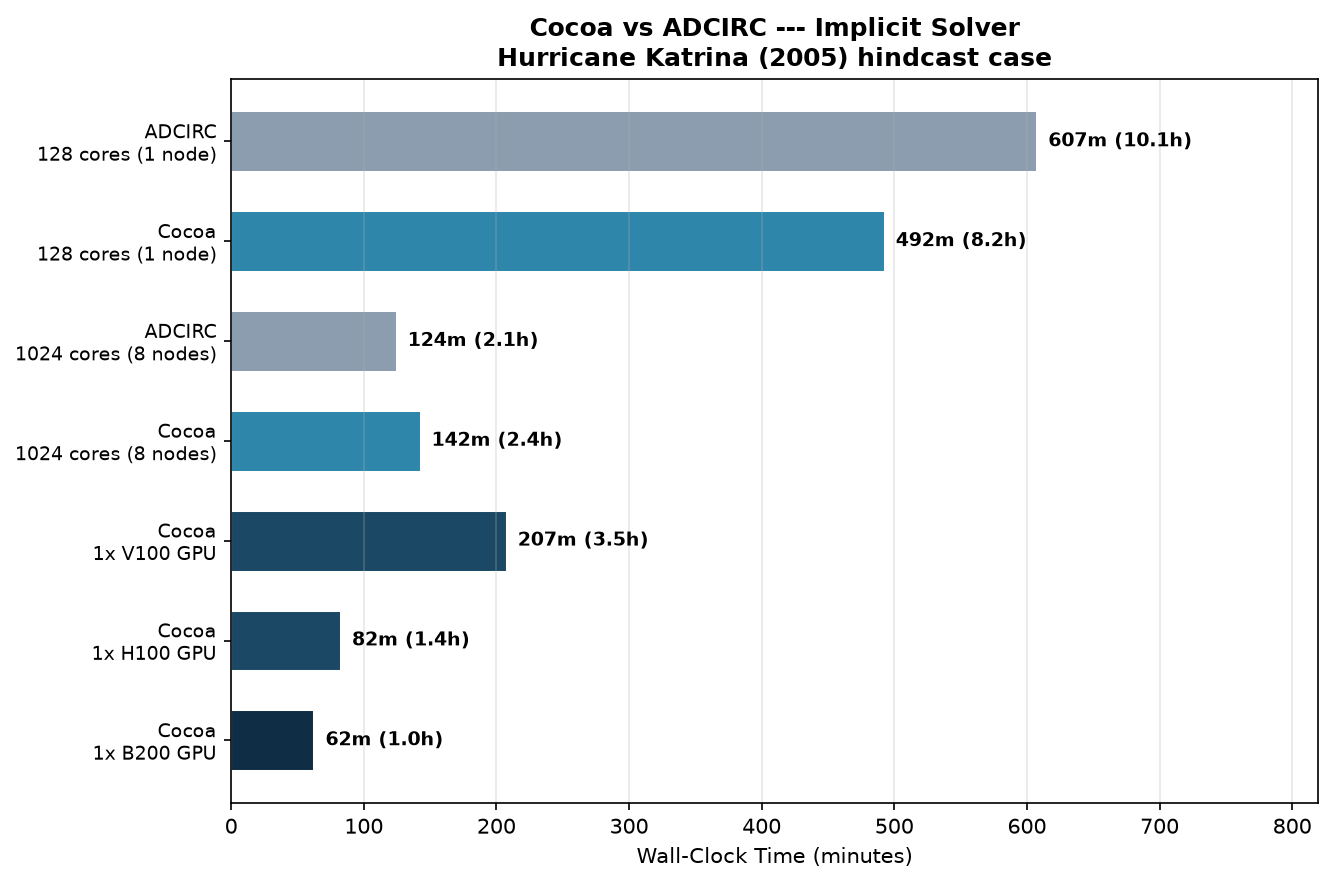
Fig. 9 Wall-clock time for the implicit solver (dt=2s) on the 1.57M-node Hurricane Katrina hindcast.
Model |
Hardware |
Wall Time |
|---|---|---|
ADCIRC |
128 cores (1 node) |
607m (10.1h) |
Cocoa |
128 cores (1 node) |
492m (8.2h) |
ADCIRC |
1024 cores (8 nodes) |
124m (2.1h) |
Cocoa |
1024 cores (8 nodes) |
142m (2.4h) |
Cocoa |
1x V100 GPU |
207m (3.5h) |
Cocoa |
1x H100 GPU |
82m (1.4h) |
Cocoa |
1x B200 GPU |
62m (1.0h) |
Explicit Solver Results
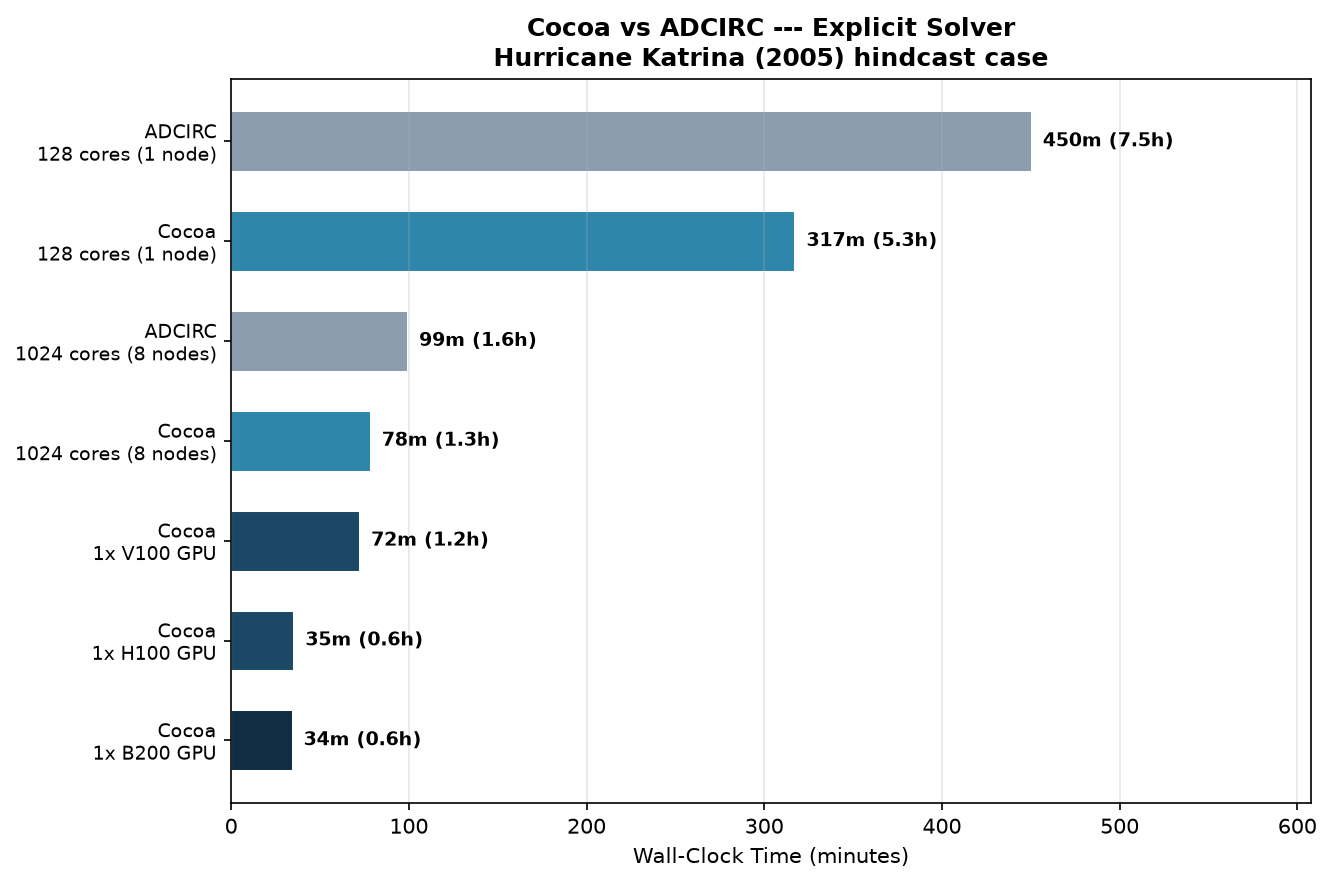
Fig. 10 Wall-clock time for the explicit lumped-mass solver (dt=2s) on the 1.57M-node Hurricane Katrina hindcast.
Model |
Hardware |
Wall Time |
|---|---|---|
ADCIRC |
128 cores (1 node) |
450m (7.5h) |
Cocoa |
128 cores (1 node) |
317m (5.3h) |
ADCIRC |
1024 cores (8 nodes) |
99m (1.6h) |
Cocoa |
1024 cores (8 nodes) |
78m (1.3h) |
Cocoa |
1x V100 GPU |
72m (1.2h) |
Cocoa |
1x H100 GPU |
35m (0.6h) |
Cocoa |
1x B200 GPU |
34m (0.6h) |
CPU-MPI Scaling
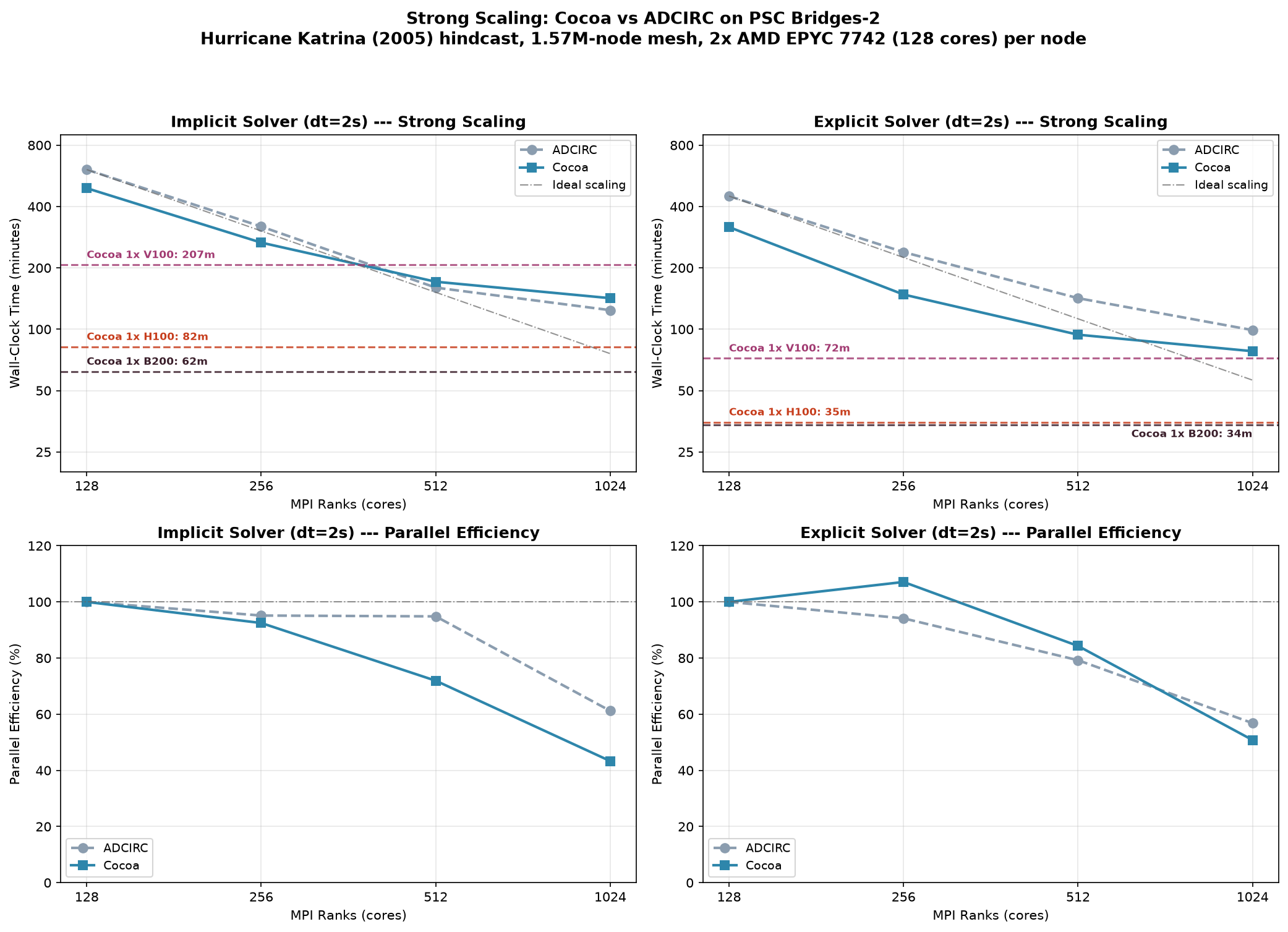
Fig. 11 Top: log-log scaling of wall-clock time vs MPI ranks on PSC Bridges-2, one panel per solver, with horizontal reference lines marking Cocoa’s single-GPU wall times for the same solver. Bottom: parallel efficiency relative to each configuration’s own 128-core run.
Wall-clock time in minutes by MPI rank count:
Ranks |
Cocoa Implicit |
ADCIRC Implicit |
Cocoa Explicit |
ADCIRC Explicit |
|---|---|---|---|---|
128 |
492 |
607 |
317 |
450 |
256 |
266 |
319 |
148 |
239 |
512 |
171 |
160 |
94 |
142 |
1024 |
142 |
124 |
78 |
99 |